
Welcome! I’m Haosen.
I am an incoming Ph.D. student in Computer and Information Science at the ![]() University of Pennsylvania, affiliated with the GRASP Lab and IDEAS Center, advised by Prof. René Vidal. Previously, I was a Master’s student at
University of Pennsylvania, affiliated with the GRASP Lab and IDEAS Center, advised by Prof. René Vidal. Previously, I was a Master’s student at ![]() Northwestern University, advised by Prof. Manling Li at the MLL Lab, in collaboration with the Stanford Vision and Learning Lab, and a research intern at the Shanghai AI Lab. I received my BSc in Data Science and Technology from the
Northwestern University, advised by Prof. Manling Li at the MLL Lab, in collaboration with the Stanford Vision and Learning Lab, and a research intern at the Shanghai AI Lab. I received my BSc in Data Science and Technology from the ![]() Hong Kong University of Science and Technology, advised by Prof. Chi-Keung Tang and Prof. Yu-Wing Tai.
Hong Kong University of Science and Technology, advised by Prof. Chi-Keung Tang and Prof. Yu-Wing Tai.
Happy to chat about ideas, new directions, collaborations, or opportunities!
📢 News
- 2026.05: ProgressLM was selected for an Oral presentation at ACL 2026!
- 2026.04: One paper accepted by ACL 2026 (Main)!
- 2026.01: One paper accepted by ICLR 2026!
- 2026.01: New work coming to arXiv: ProgressLM: Towards Progress Reasoning in Vision-Language Models.
📚 Publications
*Equal contribution. †Corresponding author/Co-advisor. ‡Project leader.
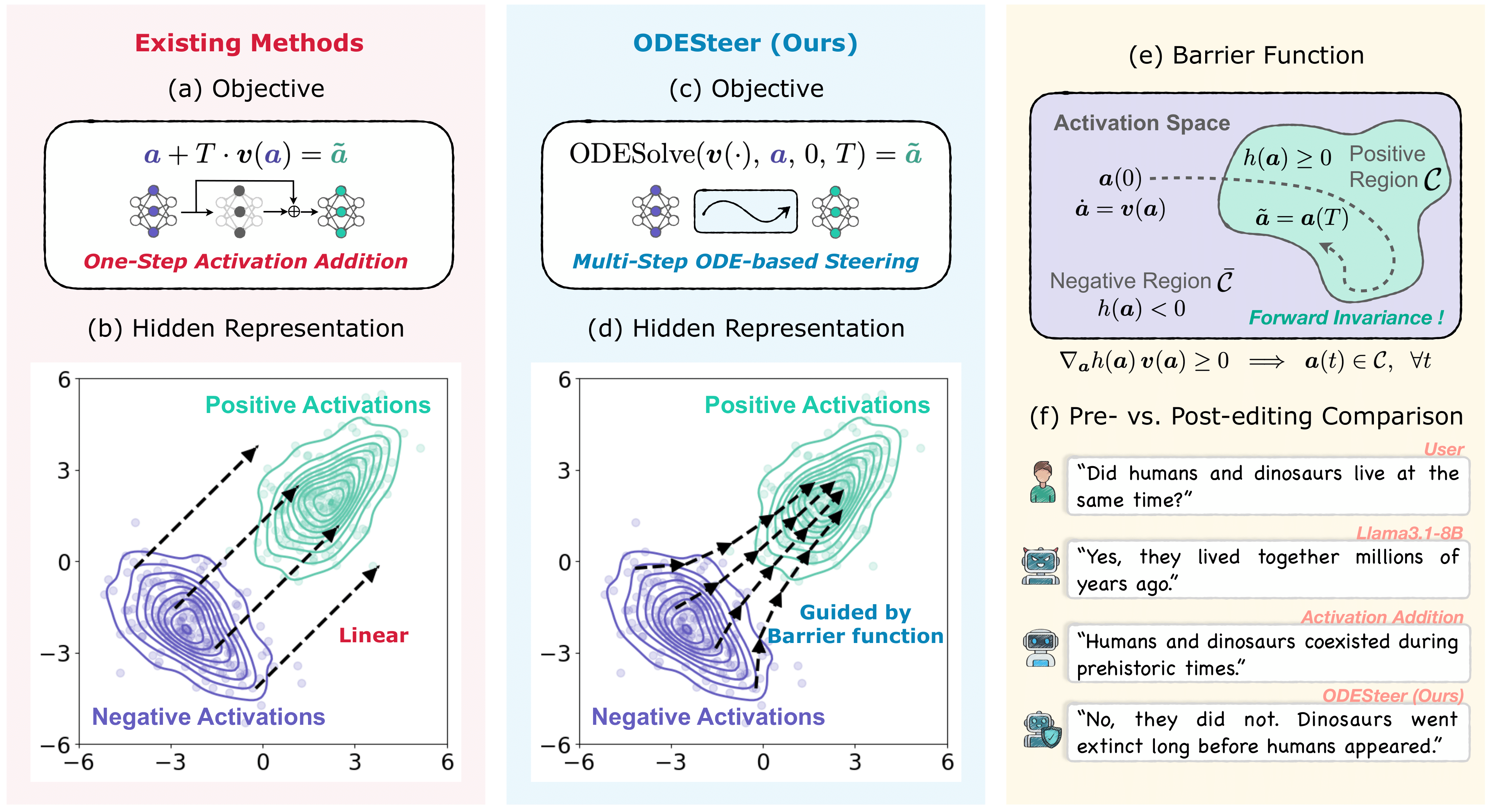
ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
Haosen Sun*, Hongjue Zhao*, Jiangtao Kong, Xiaochang Li, Qineng Wang, Liwei Jiang, Qi Zhu, Tarek F. Abdelzaher, Yejin Choi, Manling Li†, Huajie Shao†
ICLR 2026
- A unified ODE-based framework for multi-step and adaptive activation steering guided by barrier functions.
- Consistent gains on TruthfulQA (+5.7%), RealToxicityPrompts (+2.4%), UltraFeedback (+2.5%).

ProgressLM: Towards Progress Reasoning in Vision-Language Models
Jianshu Zhang*, Chengxuan Qian*, Haosen Sun, Haoran Lu, Dingcheng Wang, Letian Xue, Han Liu
Oral @ ACL 2026
ICLR 2026 Workshop on World Models
- PROGRESS-BENCH: a benchmark for long-horizon progress reasoning in VLMs, with controlled modality, viewpoint, and answerability.
- Reveals that vanilla VLMs struggle to estimate task progress from a single observation; ProgressLM-3B (SFT + RL) addresses this via episodic retrieval and mental simulation.
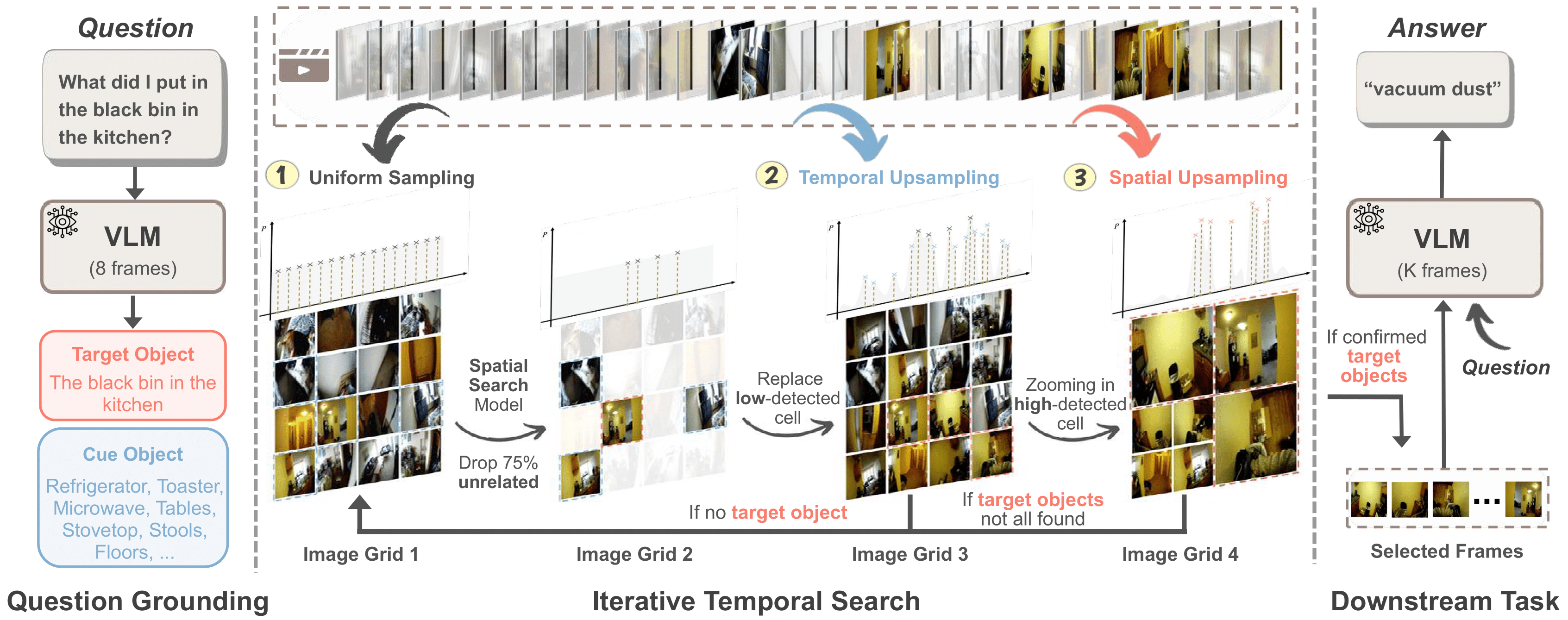
T*: Re-thinking Temporal Search for Long-Form Video Understanding
Jinhui Ye*, Zihan Wang*, Haosen Sun, Keshigeyan Chandrasegaran, Zane Durante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Fei-Fei Li, Jiajun Wu, Manling Li
CVPR 2025
Oral @ ICCV 2025 Workshop on LongVid-Foundations
Featured by Stanford AI Blog
- We introduce LongVideoHaystack (LV-Haystack), a 480-hour dataset for keyframe search in long videos, with 15,092 human-annotated instances (SOTA: 2.1% Temporal F1).
- Our framework T* reframed temporal search as spatial search with adaptive zooming, boosting GPT-4o from 50.5% to 53.1% and LLaVA-OV from 56.5% to 62.4% on LongVideoBench XL.
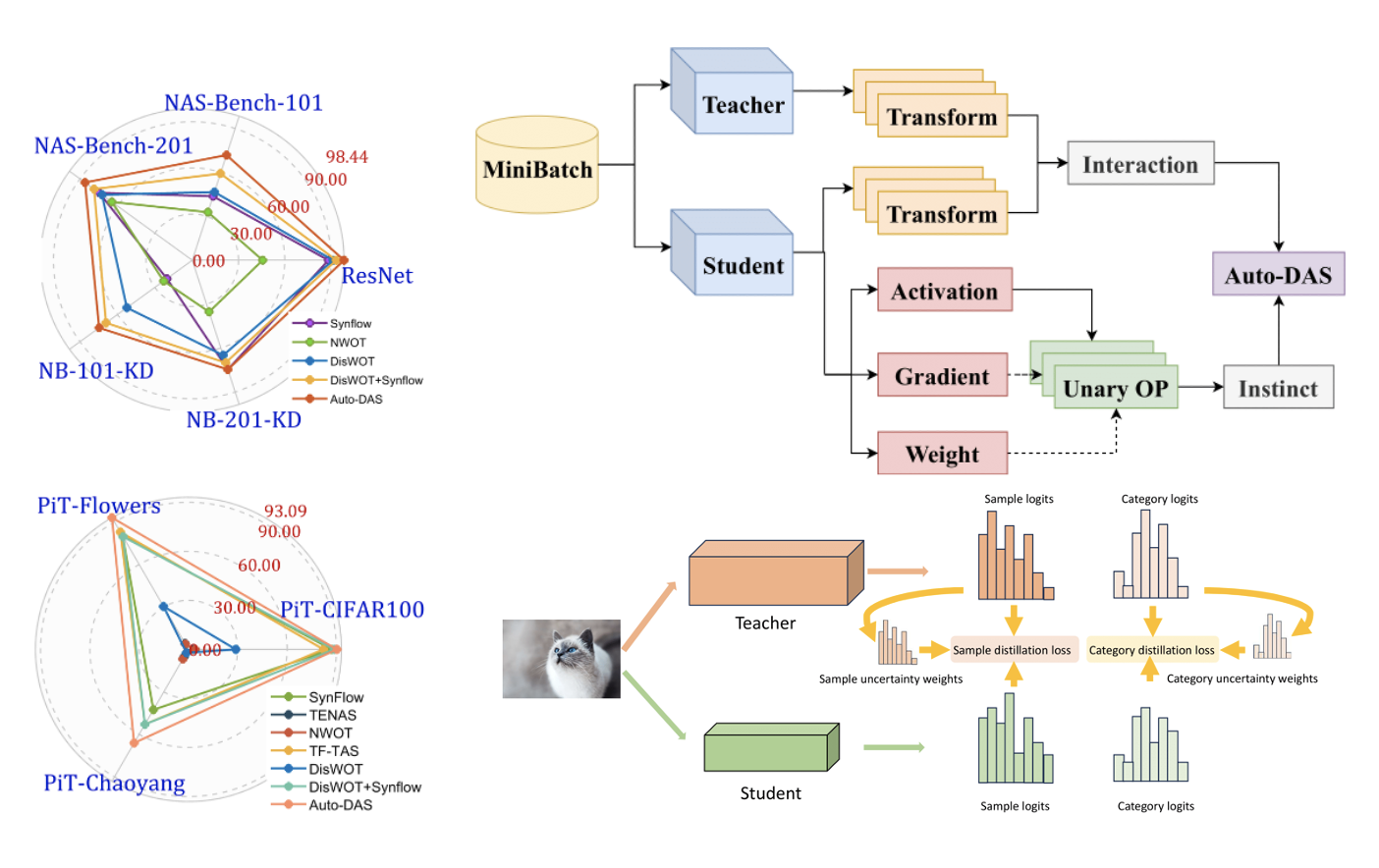
Auto-DAS: Automated Proxy Discovery for Training-free Distillation-aware Architecture Search
Haosen Sun, Lujun Li†, Peijie Dong, Zimian Wei, Shitong Shao
ECCV 2024
- We present Auto-DAS, an automatic proxy discovery framework using an Evolutionary Algorithm (EA) for training-free Distillation-aware Architecture Search (DAS).
- Auto-DAS generalizes well to various architectures and search spaces (e.g. ResNet, ViT, NAS-Bench-101, and NAS-Bench-201), achieving state-of-the-art results in both ranking correlation and final searched accuracy.
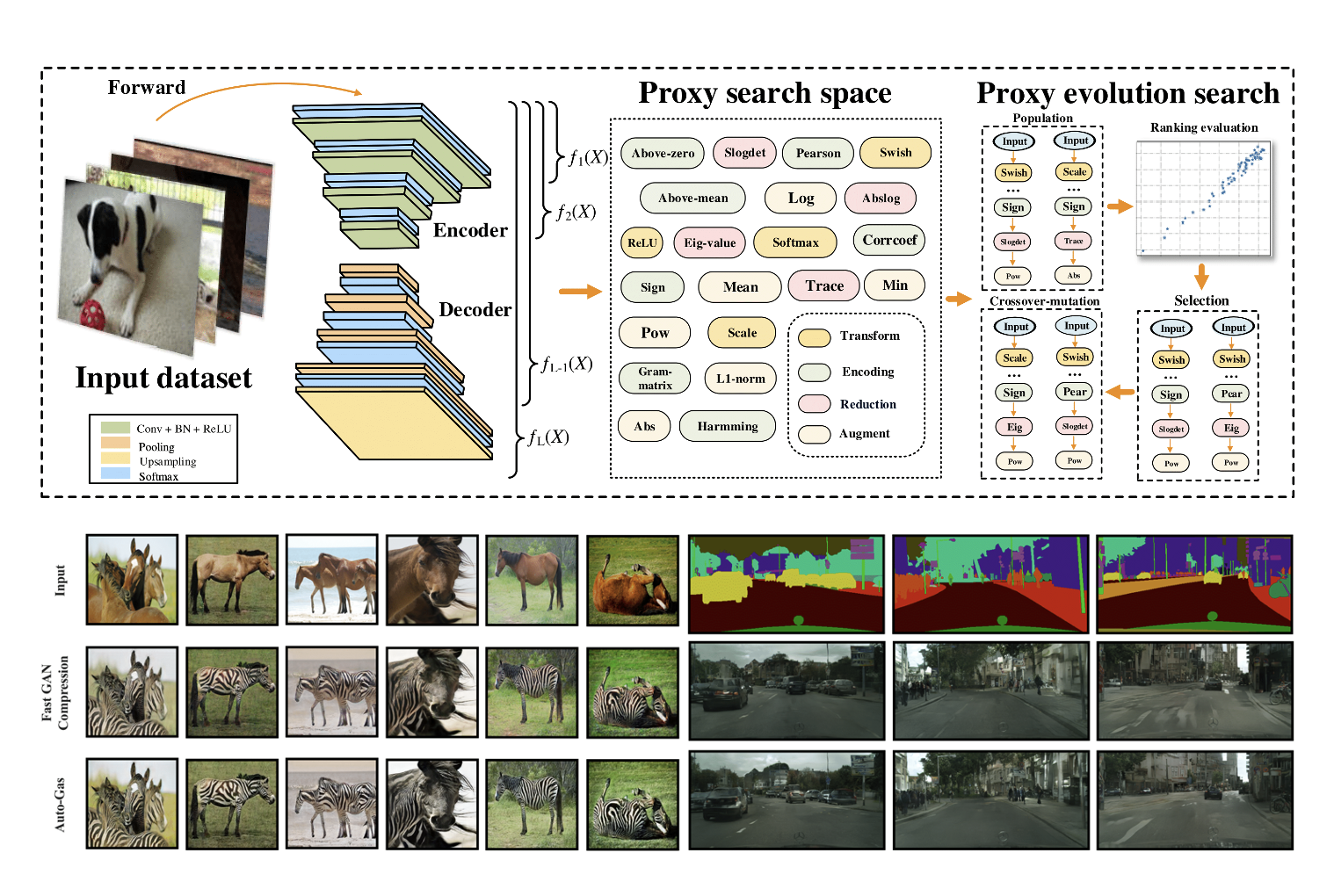
Auto-GAS: Automated Proxy Discovery for Training-free Generative Architecture Search
Lujun Li, Haosen Sun, Shiwen Li, Peijie Dong, Wenhan Luo, Wei Xue, Qifeng Liu†, Yike Guo†
ECCV 2024
- We introduce Auto-GAS, the first training-free Generation Architecture Search (GAS) framework enabled by an auto-discovered proxy, which achieves competitive scores with 110× faster search than GAN Compression.

Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
Han Jiang*, Haosen Sun*, Ruoxuan Li*, Yu-Wing Tai, Chi-Keung Tang
arXiv Preprint 2023
- Inpaint4DNeRF can generate prompt-based objects guided by the seed images and their 3D proxies while preserving multiview consistency. Our generative baseline framework is general and can be readily extended to 4D dynamic NeRFs.
🏆 Honors and Awards
- HKUST Dean’s List Awards
- Silver Medal in CVPR’24 Workshop (Image Matching Challenge 2024 - Hexathlon)
- Silver Medal in Kaggle Competition (Google - Fast or Slow? Predict AI Model Runtime)
- Nominated for the Mr. Armin and Mrs. Lillian Kitchell Undergraduate Research Award
- Kerry Holdings Limited Scholarship (HKUST Admissions Scholarship, HK$280,000)
- Bronze Medal and the First Prize in the 36th Chinese Physics Olympiad (CPHO), Top 0.1%
{kind=link}
{kind=link}
🎓 Education
Ph.D. in Computer and Information Science
![]() University of Pennsylvania, Philadelphia, PA
University of Pennsylvania, Philadelphia, PA
M.S. in Computer Science
![]() Northwestern University, Evanston, IL
Northwestern University, Evanston, IL
BSc in Data Science and Technology
![]() Hong Kong University of Science and Technology (HKUST), Hong Kong
Hong Kong University of Science and Technology (HKUST), Hong Kong
🔍 Academic Service
🏢 Internships
Research Intern
Shanghai Artificial Intelligence Laboratory, China
Research Intern
Hong Kong Generative AI Research and Development Center (HKGAI), Hong Kong